上一篇 《负载均衡概述》
在前面的文章 《负载均衡概述》 中,主要对负载均衡的实现做了一系列的描述,接下来我们来一起看看关于负载均衡的算法。
服务消费者从服务配置中心获取到服务的地址列表后,需要选取其中一台发起RPC调用,这时就需要用到具体的负载均衡算法。常用的负载均衡算法有 轮询法、加权轮询法、随机法、加权随机法、源地址哈希法、最小连接法 等。
1. 轮询法
轮询法是指将请求按顺序轮流地分配到后端服务器上,均衡地对待后端的每一台服务器,不关心服务器实际的连接数和当前系统负载。
轮询法的示意图如下:
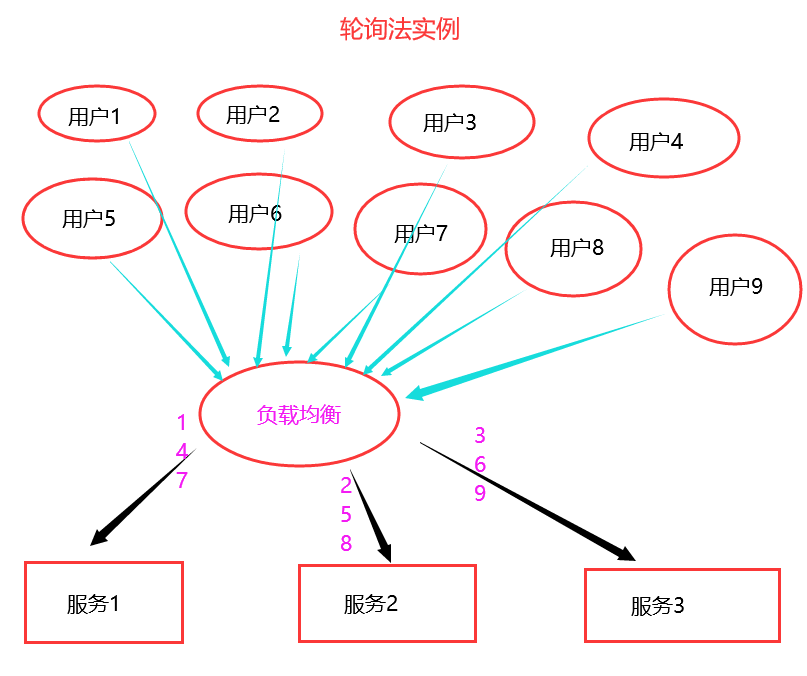
从上图不难看出,假设现在有9个用户端请求,3台后端服务器。当第一个请求到达负载均衡服务器时,负载均衡服务器会将这个请求分派到后端服务1,;当第二个请求到来时,负载均衡服务会将这个请求分配到后端服务器2;当第三个请求到来时,负载均衡服务会将这个请求分派到后端服务器3;当第四个请求到来时,则就会被分派到服务器1了......以此类推。
2. 加权轮询法
加权轮询法是指根据真实服务器的不同处理能力来调度访问请求,这样可以保证处理能力强的服务器处理更多的访问流量。简单的轮询法并不考虑后端机器的性能和负载差异。加权轮询法可以很好的处理这一问题,它将按照顺序且按照权重分派给后端服务器:给性能高、负载低的机器配置较高的权重,让其处理较多的请求;给性能低、负载高的机器配置较低的权重,让其处理较少的请求。
如下图所示,后端服务器1配赋予权重值1,服务器2被赋予权重值2,服务器3被赋予权重值3,那么在轮询法的基础上,同样的请求将会发生如下图所展示的那样,权重值高的分配到的请求就会相应的多。这就是加权轮询法。
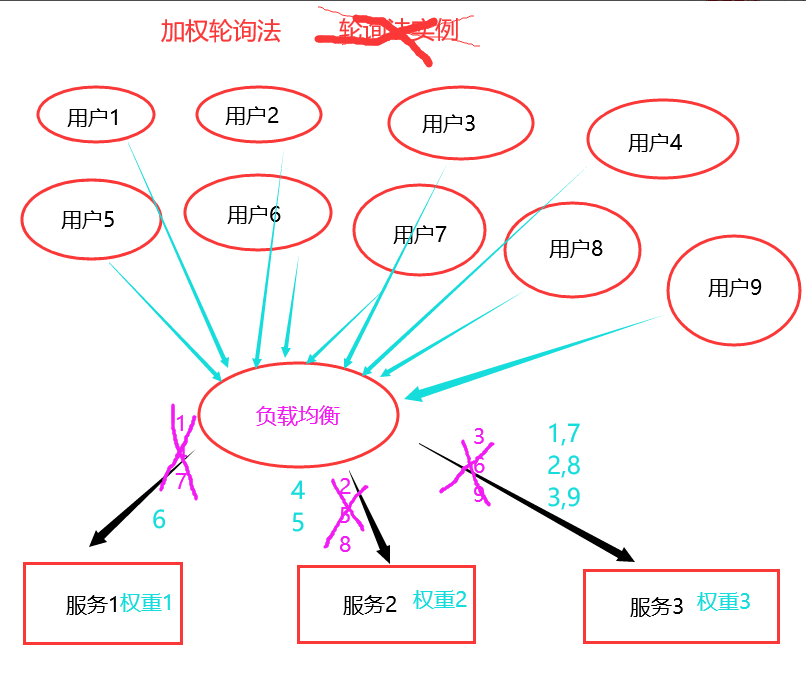
3. 随机法
随机法也很简单,就是随机选择一台后端服务进行请求处理。由于每次挑中服务的概率都一样,因此客户端的请求可以被均匀的分派到所以的服务容器上。由概率统计理论可以得知,随着调用量的增大,其实实际效果越来越近乎于平均分配流量到每一个服务上,某种程度上,也相当于轮询法的效果。
4. 加权随机法
顾名思义,加权随机法跟加权轮询法很类似,根据服务配置的不同和负载情况配置不同的权重。不同的是,它是按照权重来随机选取服务的,而非顺序。
5. 源地址哈希法
源地址哈希(Hash)是根据获取客户端的IP地址,通过哈希函数计算得到一个数值,用该数值对服务的列表的大小进行取模运算,得到的结果便是客户端要访问服务端的序号。采用源地址哈希法进行负载均衡,同一个IP地址的客户端,当后端服务列表不变时,它每次都会映射到同一个服务里面进行访问。源地址哈希法的缺点是,当后端服务个数增加或者减少时,采用简单的哈希取模的方法会使得命中率大大降低,这个问题可以采用一致性哈希法来解决。
6. 用一致性哈希法
用一致性哈希(Hash) 算法解决了分布式环境下服务个数增多或者减少时,简单的取模运行法无法获取值较高命中率的问题。通过虚拟节点的使用,一致性哈希算法可以均匀分担服务容器的负载,使得这一算法更具现实意义。正因如此,一致性哈希算法被广泛应用于分布式系统中。
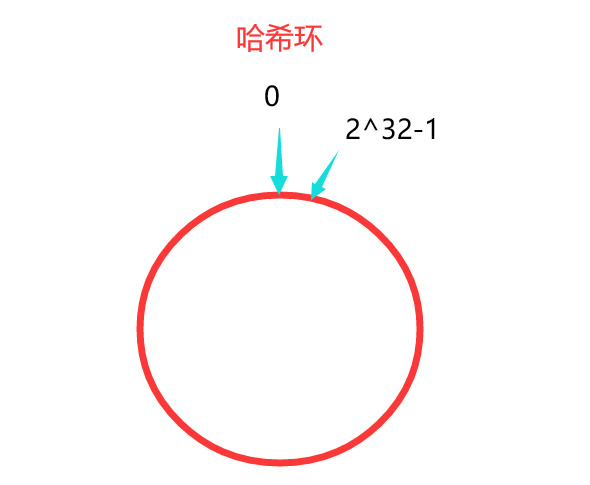
一致性哈希算法通过哈希环的数据结构实现。环的起点是0,终点是2^32-1,并且起点与终点;连接,哈希环中间的整数按逆时针分布,故哈希环的整数分布范围是 [0, 2^32-1],如下图:
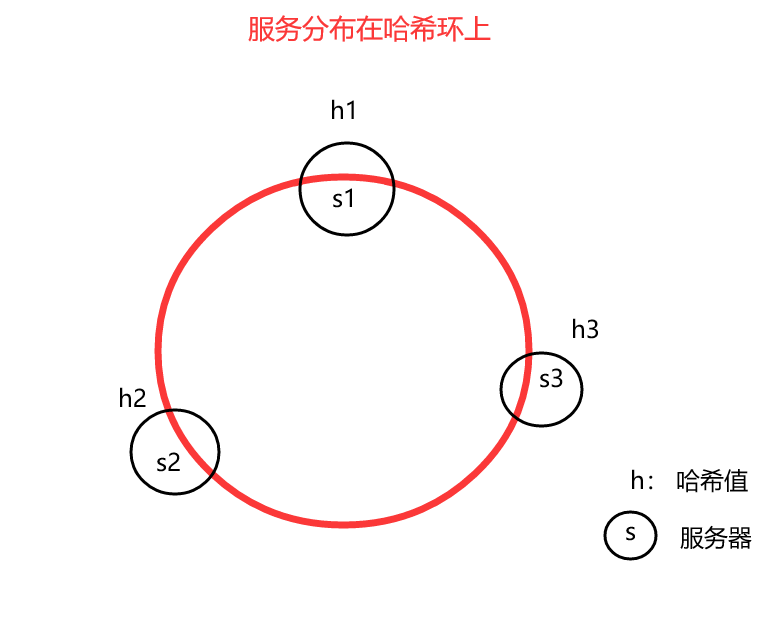
在负载均衡中,首先为每一台服务器或者每一个服务容器计算一个哈希值,然后把这些哈希值放置在哈希环上。假设现在有3台服务:s1, s2, s3 ,他们计算得到的哈希值分别是 h1, h2, h3 ,那么它们在哈希环上的位置如下图所示:
然后接下来计算每一个请求IP的哈希值:hash("192.168.0.1"),并把这些哈希值放置到哈希环上。假设现在有5个请求,对应的哈希值为:q1, q2, q3, q4, q5,放置到哈希环上的位置如下图所示:
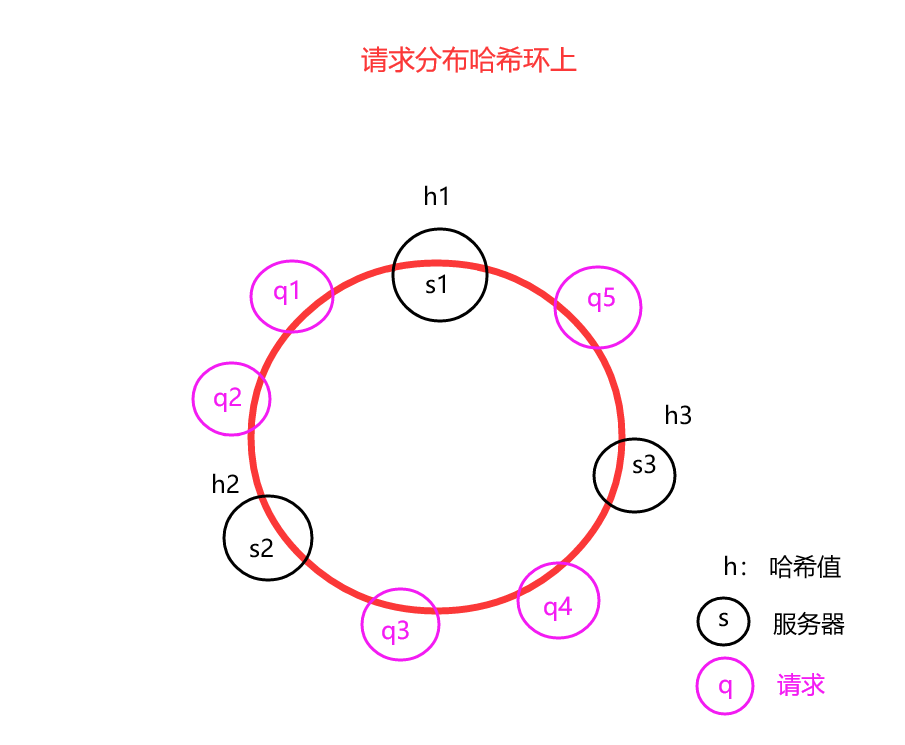
接下来就是为每一个请求找到对应的服务上去,在哈希环上顺时针查找距离这个请求的哈希值最近的服务容器上,如下图列举所示:

对应线上业务,增加或者减少一台机器的部署是常有的事情。增减服务容器只会影响相邻的服务容器,这就导致了添加服务容器时只会分担其中一台服务容器的负载,删除服务容器时会把负载全部转移到相邻的一个服务容器上去,这都不是我们希望看到的。
更希望是:
- 增加服务容器时,新的机器可以合理的分担所有机器的负载。
- 删除服务容器时,多出来的负载可以均匀的分给剩下的服务容器。
那么,举个例子,比如,系统中只有两个服务容器(或者两台服务器),由于某种原因下线了一个节点B,此时必然造成大量数据集中在另外一个节点上。为此,可以引入虚拟节点来解决负载不均衡的问题,即对每一个服务节点计算多个哈希,每个计算结构位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器IP或者主机名或者服务容器编号的后面增加编号来实现。例如上面提到的情况,可以为每台服务容器计算3个虚拟节点,定位到对应的哈希环上,形成虚拟节点。同时数据定位算法不变,只是多了一些虚拟节点。这样就解决了服务节点少时数据倾斜的问题,在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
相信很多小伙伴有接触过简单的 服务集群,比如Tomcat的集群,就是部署不同端口的多个Tomcat服务容器,通过Nginx的负载均衡来实现,这个实现里面,就可以配置上面所提到的几种负载均衡的算法,感兴趣的可以详细的去做做实践一下,后续有缘,会整理一下关于简单的负载均衡、集群案例。